
Understanding KNN by Building It From Scratch
Published:
In my experience, the most effective way to grasp math is by starting from scratch. This hands-on approach has helped me truly understand concepts like algebra, calculus, and statistics.
Recently, I’ve been applying the same approach to machine learning, specifically by implementing popular algorithms from scratch.
Here’s my version of K-Nearest Neighbors (KNN). While it may sound complicated, the math behind it is actually quite simple. And that simplicity is beautiful.
What is KNN?
KNN is a classification algorithm that works by comparing a new data point to previously seen data points. It looks at the k closest examples and uses a majority vote to assign a label.
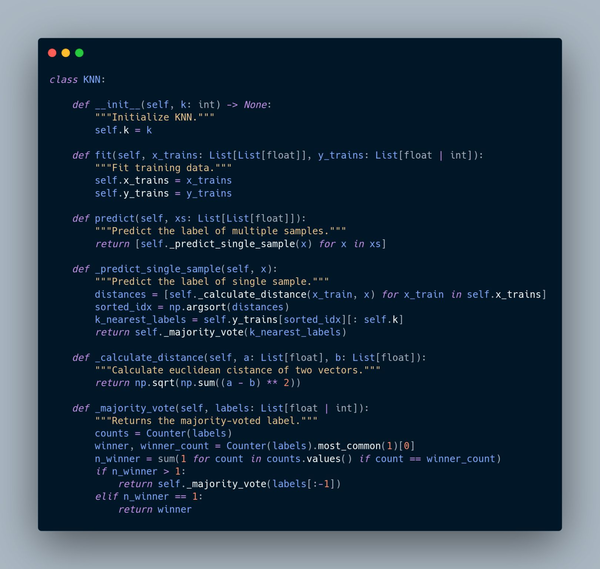
My KNN Implementation in Python
from collections import Counter
from typing import List
import numpy as np
class KNN:
def __init__(self, k: int) -> None:
self.k = k
def fit(self, x_trains: List[List[float]], y_trains: List[float | int]):
self.x_trains = x_trains
self.y_trains = y_trains
def predict(self, xs: List[List[float]]):
return [self._predict_single_sample(x) for x in xs]
def _predict_single_sample(self, x):
distances = [self._calculate_distance(x_train, x) for x_train in self.x_trains]
sorted_idx = np.argsort(distances)
k_nearest_labels = self.y_trains[sorted_idx][: self.k]
return self._majority_vote(k_nearest_labels)
def _calculate_distance(self, a: List[float], b: List[float]):
return np.sqrt(np.sum((a - b) ** 2))
def _majority_vote(self, labels: List[float | int]):
counts = Counter(labels)
winner, winner_count = counts.most_common(1)[0]
n_winner = sum(1 for count in counts.values() if count == winner_count)
if n_winner > 1:
return self._majority_vote(labels[:-1])
else:
return winner
Step-by-Step Explanation
1. __init__()
Sets how many neighbors to consider with k.
2. fit()
Stores the training data. No actual training happens here.
3. predict()
Loops through multiple samples and uses _predict_single_sample() for each.
4. _predict_single_sample()
- Calculates Euclidean distances to all training samples
- Sorts by distance
- Picks the top
kclosest labels - Returns the majority-voted label
5. _calculate_distance()
Applies the Euclidean formula:
\[\sqrt{\sum (a_i - b_i)^2}\]6. _majority_vote()
- Picks the most frequent label
- Handles ties by recursively removing the last label until there’s a clear winner